

Migrating Project for the web projects from the default environment is a question I get asked every now and then. Sometimes customers want to migrate their P4W projects to Project Operations. Another ask is migrating P4W projects from default to a Dataverse production environment.
With the Project schedule APIs, there’s an answer to these asks. P4W projects are heavily reliant on data like Organizational Units and Calendar Templates. Hence, while migrating from Project for the web in default to Project for the web in Dataverse production or Project Operations is possible, it requires good planning.
This blog post focuses on migrating Project for the web projects in a default environment to Project Operations by using Power Automate. The same concept can be applied to P4W to P4W migrations as well. Theoretically, you should also be able to use this as a concept for Project Online to P4W/Project Operations migrations as well. However, POL’s data model might require you to re-think what can and can not be migrated from POL to P4W/ProjOps.
Another use case is demo data. As this example migrates Project for the web data to staging tables, an Excel export of the data in staging tables could be extracted. The exported data could then be imported to a destination environment with matching staging tables, and the actual projects could then be created with Project schedule APIs based on the imported data.
Project for the web to Project Operations migration
The starting point of a P4W to ProjOps migration is making sure that the way rows for required settings/data in P4W are named match with how they’re named in Project Operations. As I previously mentioned, P4W relies heavily on data-based settings for running projects. Work templates, Bookable Resources, and Organizational Units are all rows in Dataverse. They have to be in place for P4W to work the way you want, and the same naturally goes for Project Operations.
Rows with matching names
For migration projects from P4W in default to ProjOps to work, make sure that data is named the same way in your source as it is in your destination. The following tables need to be considered:
- Accounts (if used in P4W, no OOTB relationship between Account and Project exists).
- Work templates.
- Organizational Units.
- Users.
- Bookable Resources.
- Roles.
If the source has a Work templated named Default Work Template, a Work template with the same name has to exist in the destination as well. If the source has a Bookable Resource named John Doe, the destination has to have a Bookable Resource named John Doe as well. You get the idea.
How a migration is done
The technical side of things is actually very simple. A chosen project and its related tables are copied from source to destination by using the Dataverse legacy connector in Power Automate. The legacy connector allows for selecting environments in the Datavere actions. This way data can be looped through in source and copied to a destination environment.
As calling the Project schedule APIs directly would easily lead to transactional inconsistency (you can read more about transactional consistency with the Project schedule APIs here), staging tables in the destination environment are used to hold all relevant data related to a project. The Project schedule APIs can then be called from a Project Staging table’s context to create projects in the destination environment.
Image 1 below illustrates the migration process.

The data model for the staging tables is very simple. A Project Staging table, used for holding information about a Project, has a parental 1:N relationship with the following supporting staging tables:
- Project Task Dependency Staging. For Task Dependencies.
- Project Task Staging. For Project Tasks.
- Project Team Member Staging. For Project Team Members.
- Resource Assignment Staging. For Resource Assignments.
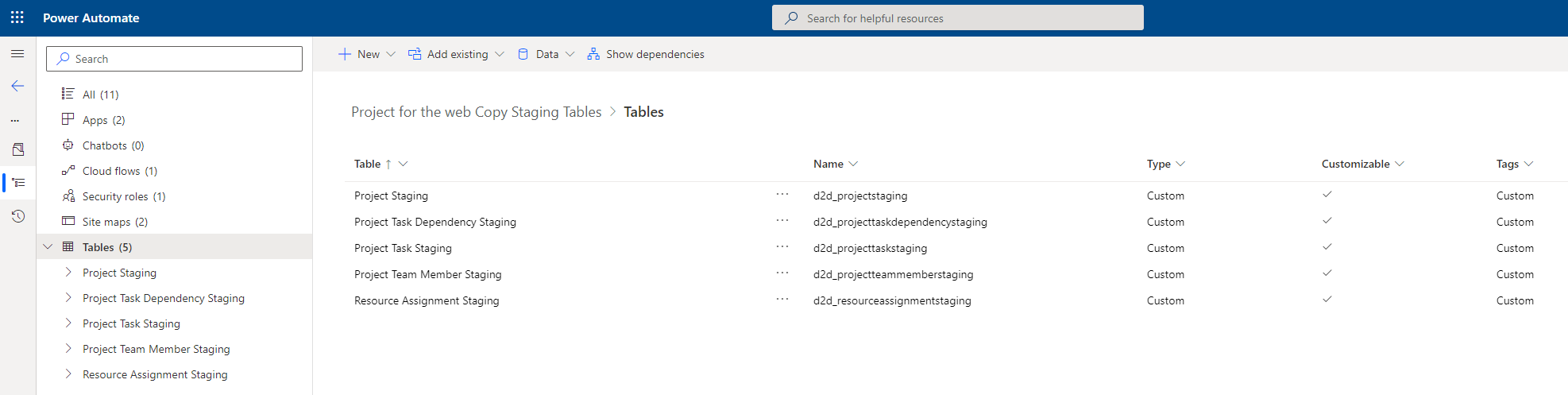
Migrating P4W data to staging tables
Let’s look at the flow that copies data from a source environment like P4W in default to a destination environment. This blog post focuses on a P4W to ProjOps migration so the destination environment has Project Operations installed in it. My examples are based on a manual trigger so that it’s easier to share the flow for the community. In reality, firing the flow off from the Project table’s command bar would probably make more sense so that multiple projects could be migrated simultaneously.
Flow – Project migrator
The initial actions are all about getting our hands on relevant data. The Get project action and its expand query are used to get our hands on the related Project, Work template, and Organizational Unit. The expand query used is msdyn_workhourtemplate($select=msdyn_name),msdyn_ContractOrganizationalUnitId($select=msdyn_name).
The Get systemuser action is used to get the user in a project’s Project Manager lookup from the Users table. The user in this lookup is usually the one who has created the project in question.
The List Project Tasks action is used to get all tasks related to the project that’s being migrated to ProjOps. The expand query in the action isn’t required as the name (msdyn_subject) of the project is already available from the aforementioned Get project action.
The List Project Task Dependencies action is used to list all dependencies between tasks for the project that’s being migrated to ProjOps. It’s critical to get the name (msdyn_subject) and the display sequence (msdyn_displaysequence) values of predecessor and successor tasks. They’re required when creating a new project in the destination environment. The expand query used is msdyn_PredecessorTask($select=msdyn_subject,msdyn_displaysequence),msdyn_SuccessorTask($select=msdyn_subject,msdyn_displaysequence),msdyn_Project($select=msdyn_subject).
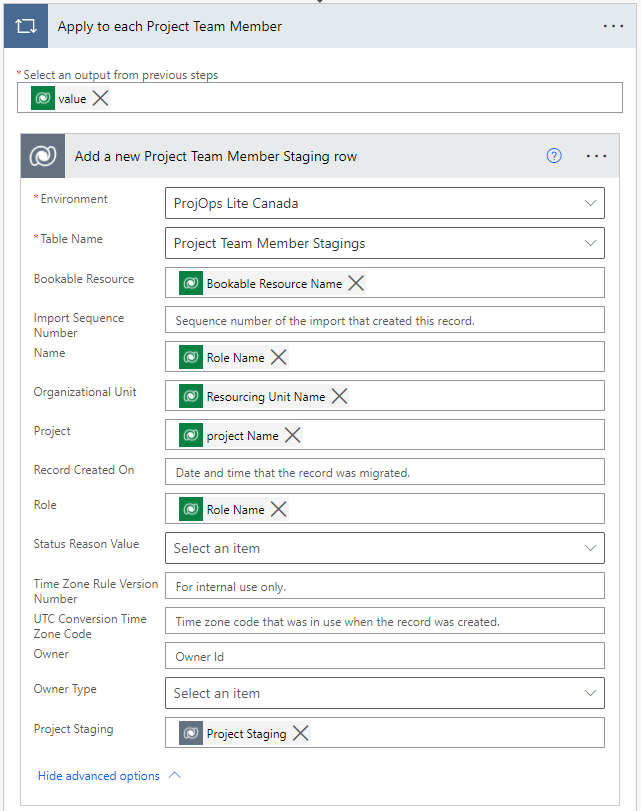
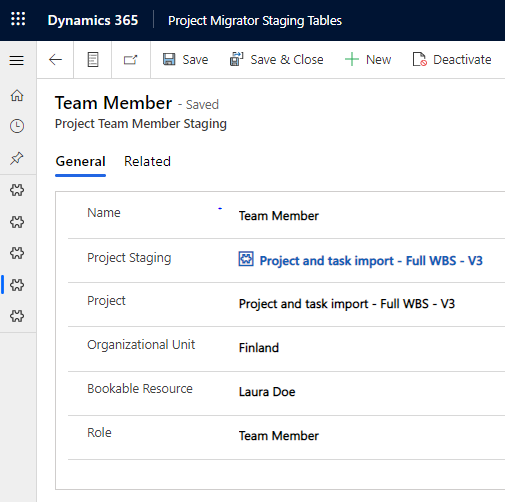
The List Project Team Members action is used to list all PTMs on the related Project. The expand query is used to get the name of the Role the PTM has (name from msdyn_resourcecategory) as well as the name of the Bookable Resource (name from msdyn_bookableresourceid). The Organizational Unit of the PTM is also behind a lookup (msdyn_name from msdyn_organizationalunit). The expand query used is msdyn_resourcecategory($select=name),msdyn_bookableresourceid($select=name),msdyn_organizationalunit($select=msdyn_name),msdyn_project($select=msdyn_subject).
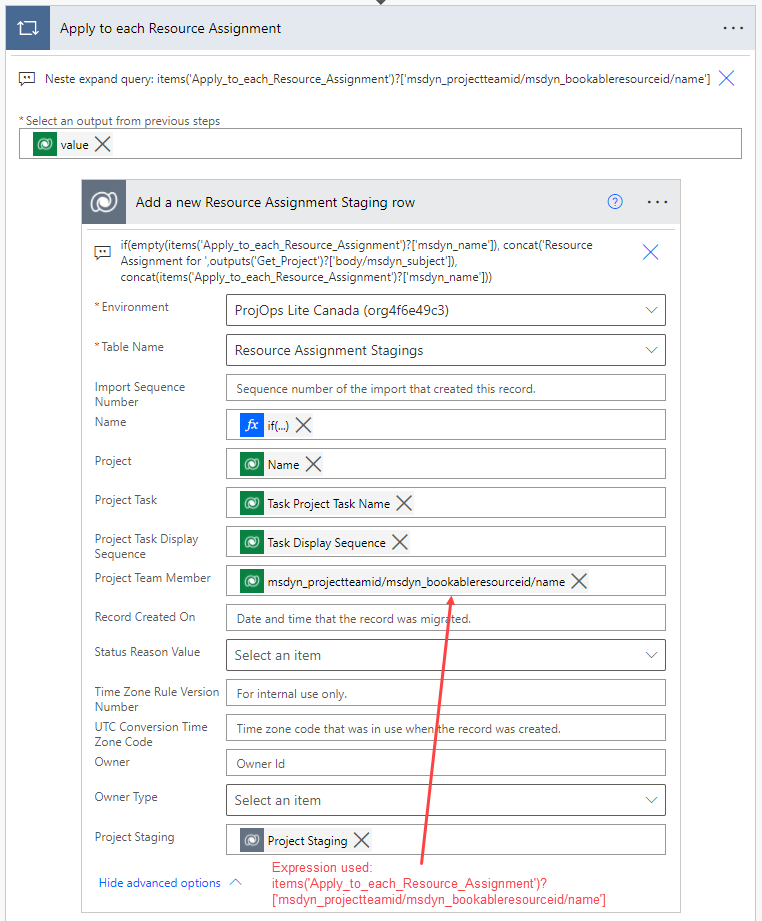
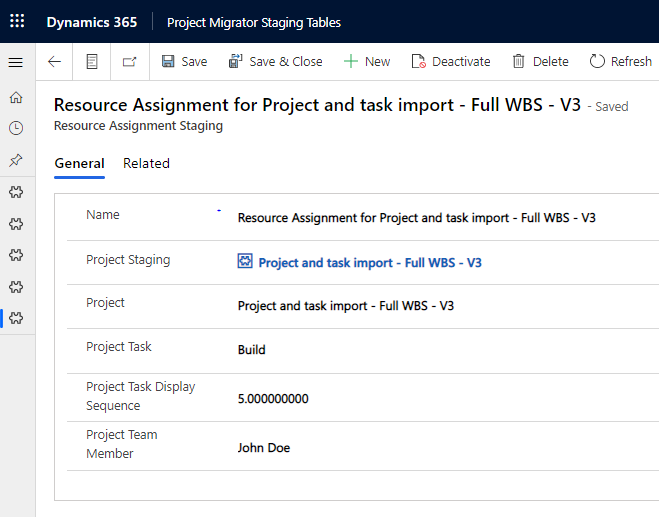
The List Resource Assignments action is where things get a little trickier. While listing all RAs related to a project is easy, we also need to get the name of the Bookable Resource for whom the RA is for. This requires a nested expand query from Resource Assignment to Project Team Member to Bookable Resource. The expand query is also used to get the related project task’s name (msdyn_subject) and display sequence (msdyn_displaysequence) so that RAs can be tied to correct tasks in the destination environment. The expand query used is msdyn_taskid($select=msdyn_subject,msdyn_displaysequence),msdyn_projectteamid($select=msdyn_bookableresourceid;$expand=msdyn_bookableresourceid($select=name)).
When using expand queries, remember that value used for the Microsoft.Dynamics.CRM.associatednavigationproperty in an expand query is case sensitive. That’s why some of the query examples above have upper case letters in them.
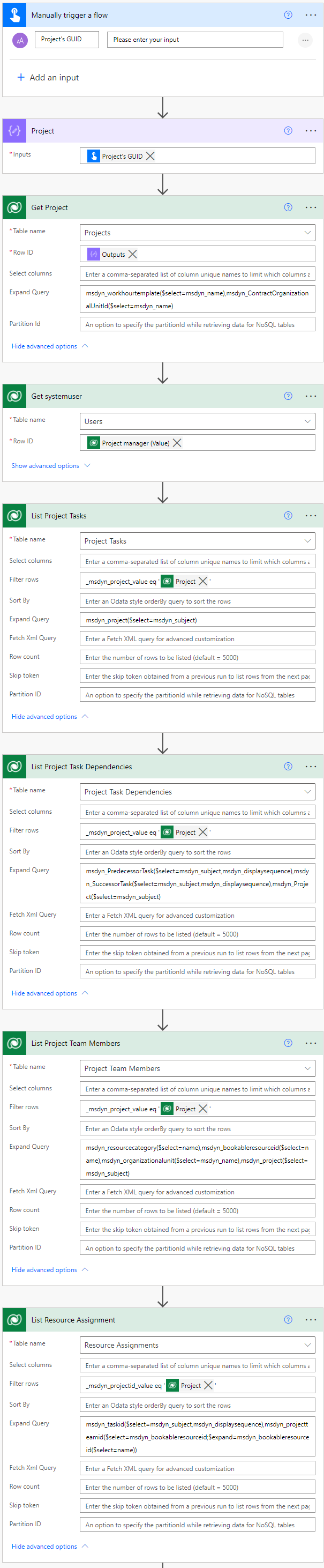
Migrating data to a destination environment
Let’s look at the next steps, which copy data to staging tables in the destination environment. The first action, seen in image 4, adds a new Project Staging row to the destination environment. Before a project is created the value of Project Created in Project Operations is set to false. The dynamic content in the action is based on the previous Get Project action. Image 5 shows a Project Staging row with data copied from a source environment with P4W.
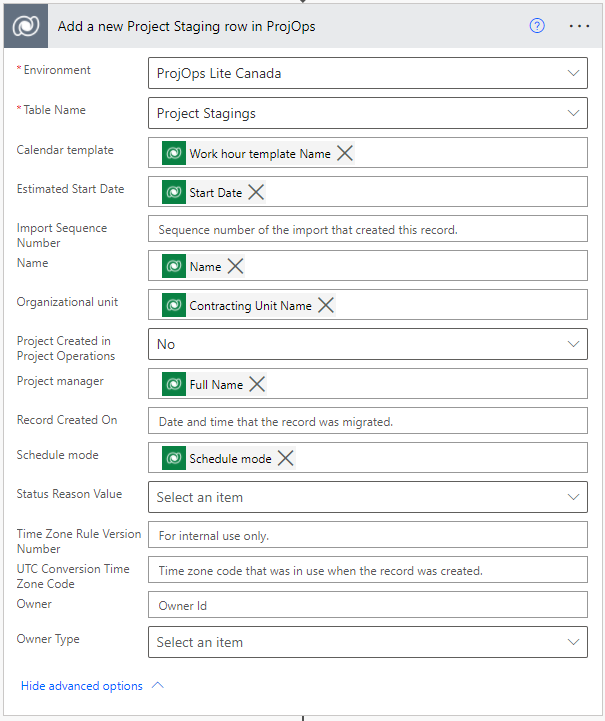
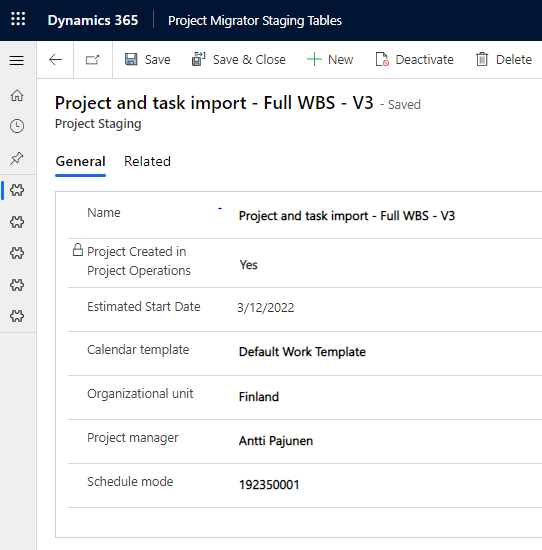
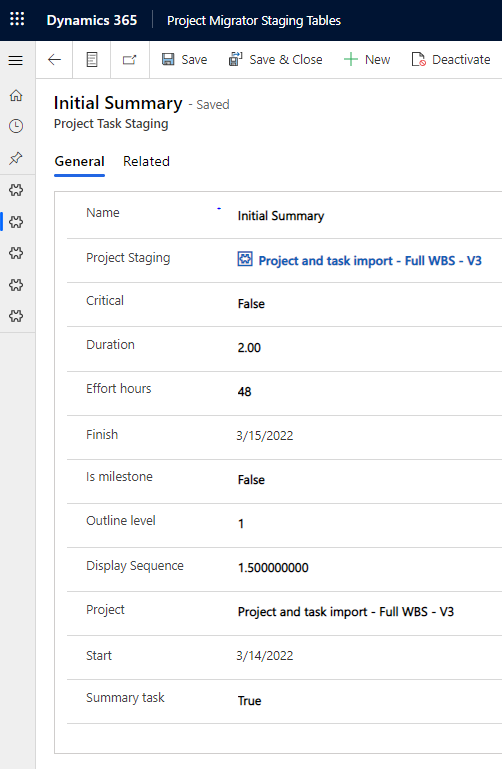
The next action seen in image 6 loops through each listed project task and copies the data from them to the Project Task Staging table in the destination environment. All dynamic content is based on the previous List Project Tasks action. The name and the display sequence of the task are enough to identify uniqueness in tasks when a new project is created down the line by calling the schedule APIs. As the value for display sequence is always unique, it can be used to identify a project task together with its name (msdyn_subject). Image 7 shows a single Project Task Staging row for the copied project.
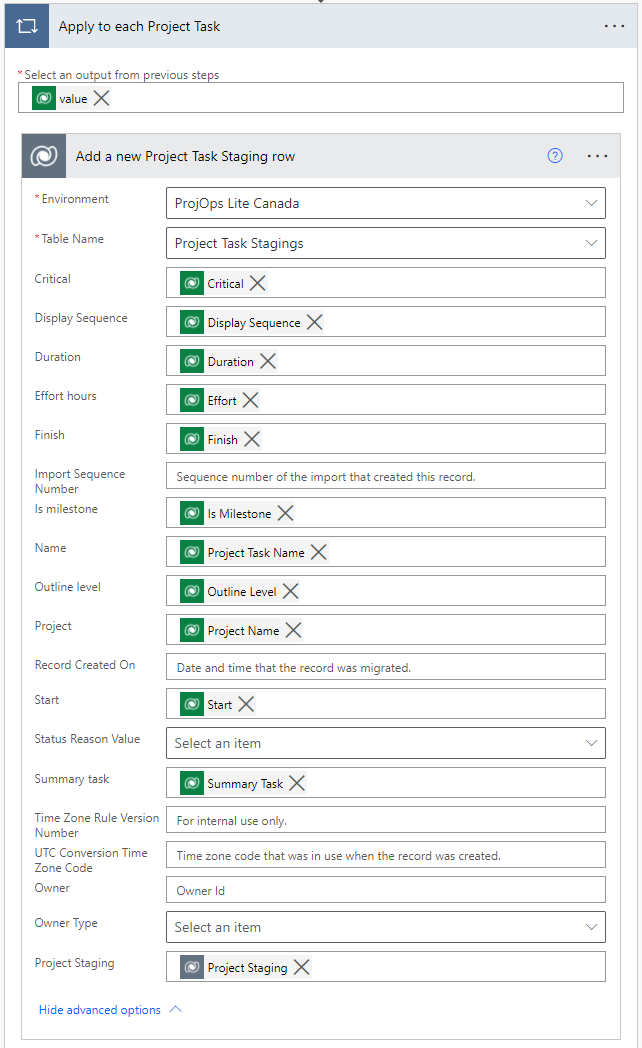
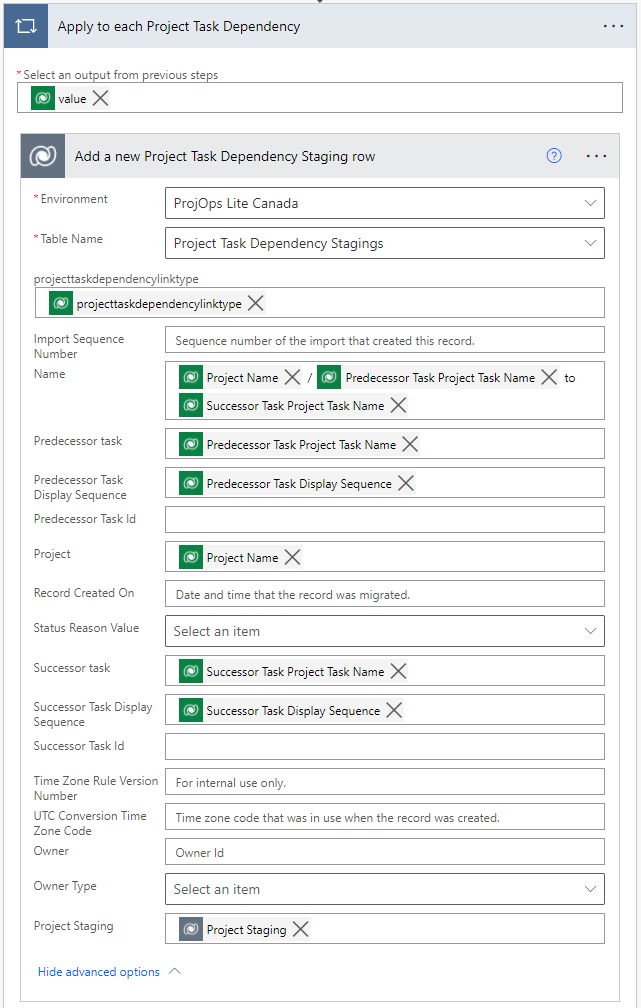
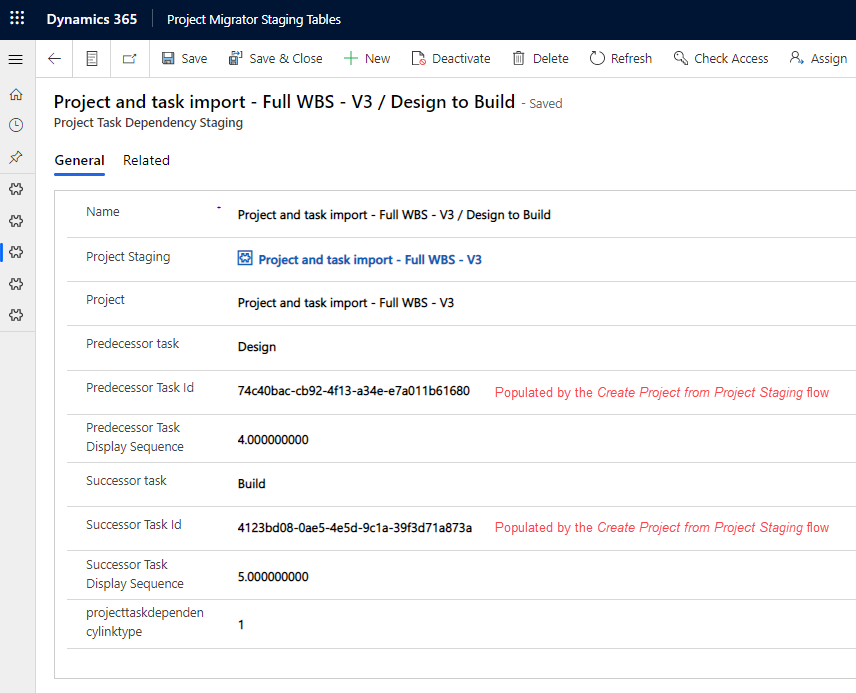
After project tasks have been created it’s time to copy dependencies to the Project Task Dependency Staging table. To point a dependency to specific tasks, a Project Task Dependency Staging row will hold values for the names and display sequences of both predecessor and successor tasks. Image 9 shows a Project Task Dependency Staging row with data copied from the source environment by the Project migrator flow. Note that the flow doesn’t populate the Predecessor Task id and Successor Task id columns. That’s done by the Create Project from Project Staging flow covered later in this post.
Copying to Project Team Member Staging follows a pattern we’re familiar with from the previous actions. Project Team Member related data is copied from source to destination as seen in images 10 and 11. Note that roles in P4W are by default Team Member for all resources except for the project manager creating the Project.
The final action of the flow copies a project’s Resource Assignments to the destination environment. As the name (msdyn_name) column on an RA is usually null, an expression is used to populate the column with a value when the original RA in the source environment doesn’t have a name. The expression used is:
if(empty(items('Apply_to_each_Resource_Assignment')?['msdyn_name']), concat('Resource Assignment for ',outputs('Get_Project')?['body/msdyn_subject']), concat(items('Apply_to_each_Resource_Assignment')?['msdyn_name']))When listing RAs, a nested expand query is necessary so that a Bookable Resource’s name can be obtained. Dynamic content doesn’t display results for nested queries so we have to use an expression in the action’s Project Team Member input box. We’re looking for the name through the following tables: msdyn_projectteamid/msdyn_bookableresourceis/name. This means that the expression needs to be written as follows:
items('Apply_to_each_Resource_Assignment')?['msdyn_projectteamid/msdyn_bookableresourceid/name']To point an RA to a specific Project Task, the task’s name and display sequence are needed on the Resource Assignment Staging row in the target environment. This way it’s possible to add a new RA for the desired task when calling the schedule APIs.
Migrating data from columns not covered in this post
This post covers a subset of columns in Project for the web’s data model. When migrating additional columns from the P4W’s data model, carefully consider which columns can be used with the Project schedule APIs. There are several columns that are considered restricted and can’t be created or edited with the APIs. See docs for the up-to-date list.
Creating a new project from staging tables
Now that all relevant data has been migrated from Project for the web to staging tables, the Project schedule APIs can be called to create projects and related rows in the destination environment. Take note of the following limitations when calling the APIs and using the Create Project from Project Staging flow:
- The flow doesn’t include catch-finally style error handling for failed calls to the Project schedule APIs. Consider adding error handling to the flow to roll back projects that are created when related data such as tasks, dependencies, team members, and assignments fail to get created.
- The flow processes tasks, dependencies, and assignments in separate OperationSets. This means that a single flow run instance will create 3 separate OperationsSets. If executing multiple simultaneous runs of the flow, the limit of 10 open OperationSets per user might be reached.
- Rows in tables that are used for basic settings and parameters must be named according to the data contained in the staging table rows. For example an Organizational Unit that is called Finland in a Project for the web source environment should also be called Finland in the staging tables in the destination environment.
Flow – Create Project from Project Staging
Let’s look at the initial actions of the Create Project from Project Staging flow. The manual trigger that’s used in the flow can be replaced in scenarios where the flow should be called from the command bar of the Project Staging table. The manual trigger processes one Project at a time and allows for the user to select whether or not to create Project Team Members and Resource Assignments from the data in the staging tables.
A variable holding @odata.type is initialized to simplify using the value down the line in JSON. Otherwise escaping the @ would be required in certain JSON schemas. I’ve used a variable as for some reason a compose action keeps erroring out and adding unwanted characters to the output. I’ve witnessed this behavior in my previous flows as well. The following rows need to be listed in the initial actions while filtering the results based on data in the staging tables:
- List Work templates. Gets us the Work template matching the one in staging tables.
- List Organization Units. Gets us a project’s Organizational Unit matching the one in staging tables.
- List Users. Gets us a project’s Project Manager from the Users table that matches the one in staging tables.
The compose actions in the parallel branches are used to compose the values returned by the previous list rows actions. The expressions used to avoid apply to each loops are:
first(body('List_Users')?['value'])?['systemuserid'] //
first(body('List_Work_templates')?['value'])?['msdyn_workhourtemplateid']
// first(body('List_Organizational_Units')?['value'])?['msdyn_organizationalunitid']
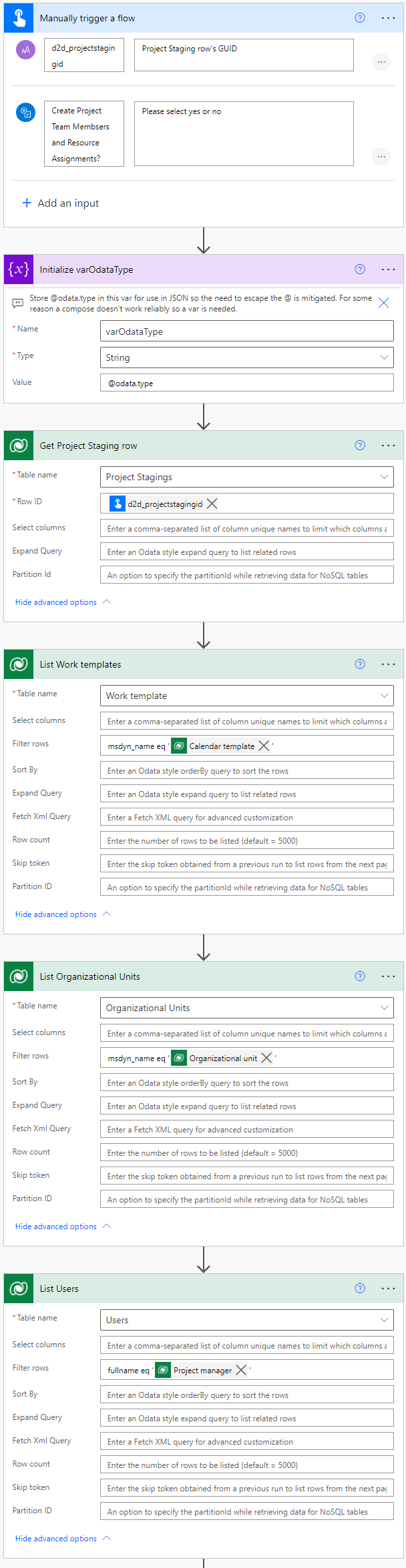

The first scope in the flow creates a new Project row and Project Tasks based on staging tables. I’ve used a trim expression to edit the msdyn_CreateProjectV1 action parameters directly as it makes creating a Project row a lot easier. Values for Work template, Project Manager (User), and Organizational Unit come from the previous compose actions. Note that as P4W doesn’t have a relationship to the Account table OOTB, a value for Account can’t be specified. It’s naturally possible to factor in Accounts with simple customizations in the source environment and in the destination’s Project Staging Table. The JSON schema used in the action is as follows:
{
"Project": {
"msdyn_subject": "@{outputs('Get_Project_Staging_row')?['body/d2d_name']}",
"msdyn_schedulemode": @{outputs('Get_Project_Staging_row')?['body/d2d_schedulemode']},
"msdyn_scheduledstart": "@{outputs('Get_Project_Staging_row')?['body/d2d_estimatedstartdate']}",
"msdyn_workhourtemplate@odata.bind": "msdyn_workhourtemplates(@{outputs('Work_template')})",
"msdyn_ContractOrganizationalUnitId@odata.bind": "msdyn_organizationalunits(@{outputs('Organizational_Unit')})",
"msdyn_projectmanager@odata.bind": "systemusers(@{outputs('User')})"
}
}The msdyn_CreateProjectV1 API creates a new project and a default bucket immediately. An OperationSet is not required for this API. The Project’s GUID is extracted in the Project Bucket compose action with the following simple expression: first(body('List_Project_Buckets')?['value'])?['msdyn_projectbucketid'].
Project Task Staging rows are then listed based on the GUID of the related Project Staging row. An OperationSet is then created so that msdyn_PssCreateV1 API can be called from the msdyn_PssCreateV1 unbound action. This API creates Project Tasks based on the listed Project Task Staging rows. Note the variable that holds @odata.type as the property for Microsoft.Dynamics.CRM.msdyn_projecttask. The JSON schema used for creating tasks is:
{
"msdyn_LinkStatus": 192350000,
"msdyn_subject": "@{items('Apply_to_each_Project_Task_Staging_row')?['d2d_name']}",
"msdyn_duration": @{items('Apply_to_each_Project_Task_Staging_row')?['d2d_duration']},
"msdyn_start": "@{items('Apply_to_each_Project_Task_Staging_row')?['d2d_start']}",
"msdyn_finish": "@{items('Apply_to_each_Project_Task_Staging_row')?['d2d_finish']}",
"msdyn_outlinelevel": @{items('Apply_to_each_Project_Task_Staging_row')?['d2d_outlinelevel']},
"msdyn_displaysequence": @{items('Apply_to_each_Project_Task_Staging_row')?['d2d_displaysequence']},
"@{variables('varOdataType')}": "Microsoft.Dynamics.CRM.msdyn_projecttask",
"msdyn_project@odata.bind": "msdyn_projects(@{outputs('Project')})",
"msdyn_projectbucket@odata.bind": "msdyn_projectbuckets(@{outputs('Project_Bucket')})"
}When the loop has run, the length of Project Task Staging rows is evaluated. This is done because a delay is required after an OperationSet (in this case the OperationSet for creating tasks) is executed. The PSS Save Service persists changes to Dataverse with a delay so a delay is needed in flow. For more information about accept vs. persist and PSS, see my post Project Operations and Project for the web: Schedule API guide for Power Automate users. Note that I’ve not added error handling to this scope to keep it simpler for testing purposes. You might want to consider adding error handling in case persisting data to Dataverse fails.

The next scope handles dependencies. A list rows action lists all Project Task Dependency Staging rows related to Project Staging row in question. A new OperationSet is then created and the Project Task Dependency rows are then looped through. Remember that at this point we already have a Project and Project Tasks created in Dataverse. This way we’re able to access tasks for the Project row in question.
Let’s look at the apply to each for Project Task Dependency rows a little closer. Our goal is to create Project Task Dependency rows so the first action to take is to list all Project Task rows inside the loop. There’s a catch though. First, we’ll list tasks where their subject (msdyn_subject) matches the value of a Project Task Dependency Staging row’s Predecessor Task column. This way we can get the GUID of a Project Task and know which dependency it belongs to as a predecessor task. The filter rows OData query is as follows:
_msdyn_project_value eq '@{outputs('Project')}' and msdyn_subject eq '@{items('Apply_to_each_Project_Task_Dependency_Staging_row')?['d2d_predecessortask']}' and msdyn_displaysequence eq @{items('Apply_to_each_Project_Task_Dependency_Staging_row')?['d2d_predecessortaskdisplaysequence']}This is what the query essentially filters:
- Project Task is related to the Project that was created in the scope Project and Tasks.
- Project Task’s subject (msdyn_subject) equals the value of the Predecessor Task column on the Project Task Dependency row currently being looped through.
- Display Sequence equals the value of Predecessor Task Display Sequence on the Project Task Dependency row currently being looped through.
The following list rows action is a repeat of the previous one, except this time successor tasks are processed. The subject (msdyn_subject) of a Project Task that matches the value of a Project Task Dependency Staging row’s Successor Task column is the one we’re after, as long as it’s related to the Project in question and the task’s Display Sequence matches the value of the Successor Task Display Sequence column.
At this point, we now have our hands on Project Tasks that are predecessors and successors to the Project Task Dependency Staging row being looped through. We can now update the Project Task Dependency Staging row with the GUIDs of the tasks by using first expressions: first(body('List_Project_Tasks_for_Predecessor_Tasks')?['value'])?['msdyn_projecttaskid'] // first(body('List_Project_Tasks_for_Successor_Tasks')?['value'])?['msdyn_projecttaskid']. We now have a Project Task Dependency Staging row in Dataverse with information about the Project Tasks that are its predecessors and successors. The next action is then to create a Project Task Dependency row by calling the msdyn_PssCreateV1 unbound action and API. The JSON schema for that is as follows:
{
"msdyn_linktype": 192350000,
"msdyn_projecttaskdependencylinktype": 1,
"msdyn_description": "Dependency between @{outputs('Update_Project_Task_Dependence_Staging_row')?['body/d2d_predecessortask']} and @{outputs('Update_Project_Task_Dependence_Staging_row')?['body/d2d_successortask']}",
"@{variables('varOdataType')}": "Microsoft.Dynamics.CRM.msdyn_projecttaskdependency",
"msdyn_Project@odata.bind": "msdyn_projects(@{outputs('Project')})",
"msdyn_PredecessorTask@odata.bind": "msdyn_projecttasks(@{outputs('Update_Project_Task_Dependence_Staging_row')?['body/d2d_predecessortaskid']})",
"msdyn_SuccessorTask@odata.bind": "msdyn_projecttasks(@{outputs('Update_Project_Task_Dependence_Staging_row')?['body/d2d_successortaskid']})"
}The final actions in the scope are to execute the OperationSet used in the scope and to add a delay for persisting changes to Dataverse. Note that I haven’t included error handling steps in this scope either so you may want to revise the flow slightly and add some.

After dependencies, a condition is used to check whether or not Project Team Members and Resource Assignments should be created or not. Some projects in the source environment might not have team members or assignments on them so the flow’s trigger allows users to opt-out of creating PTMs and RAs.
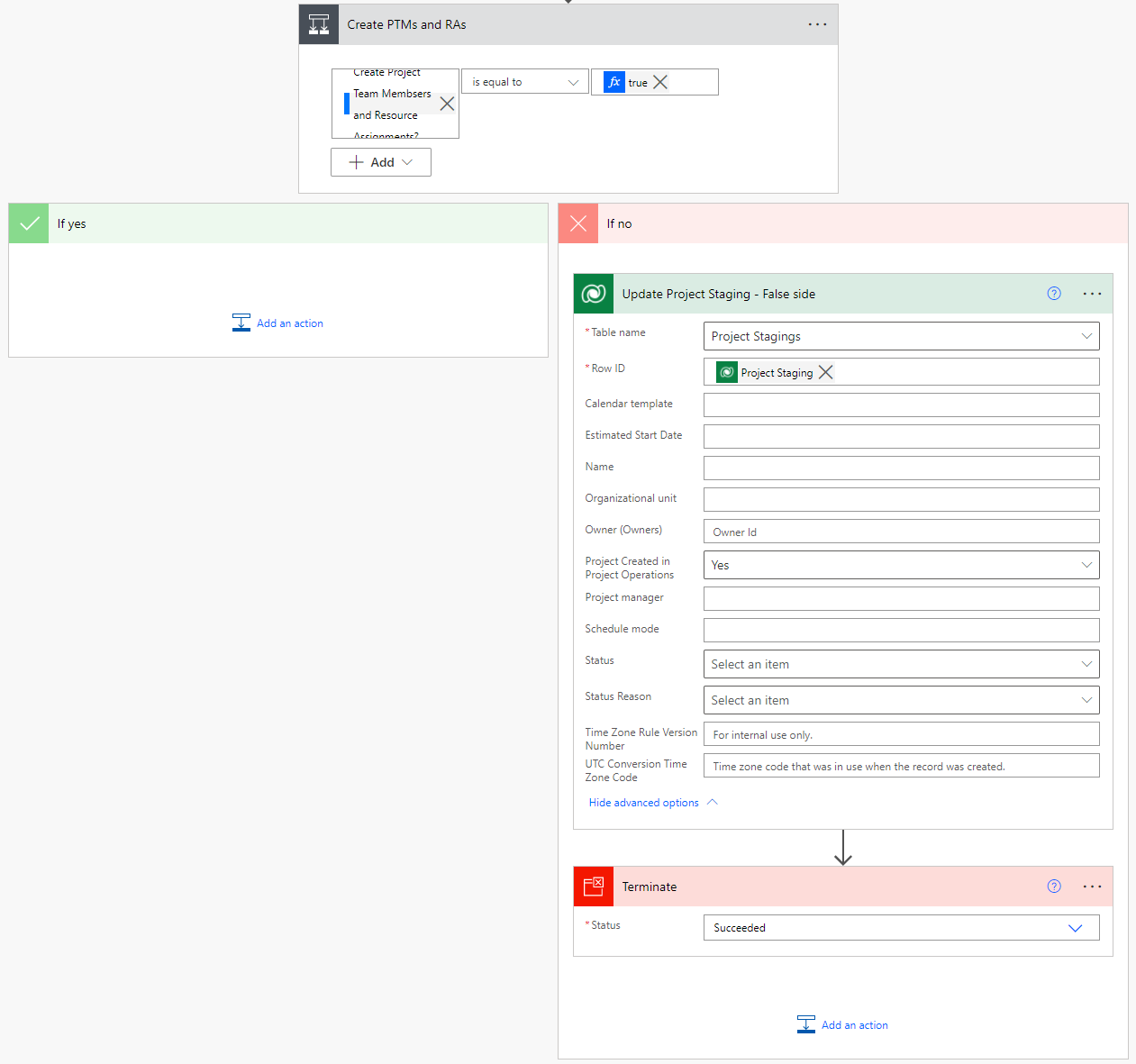
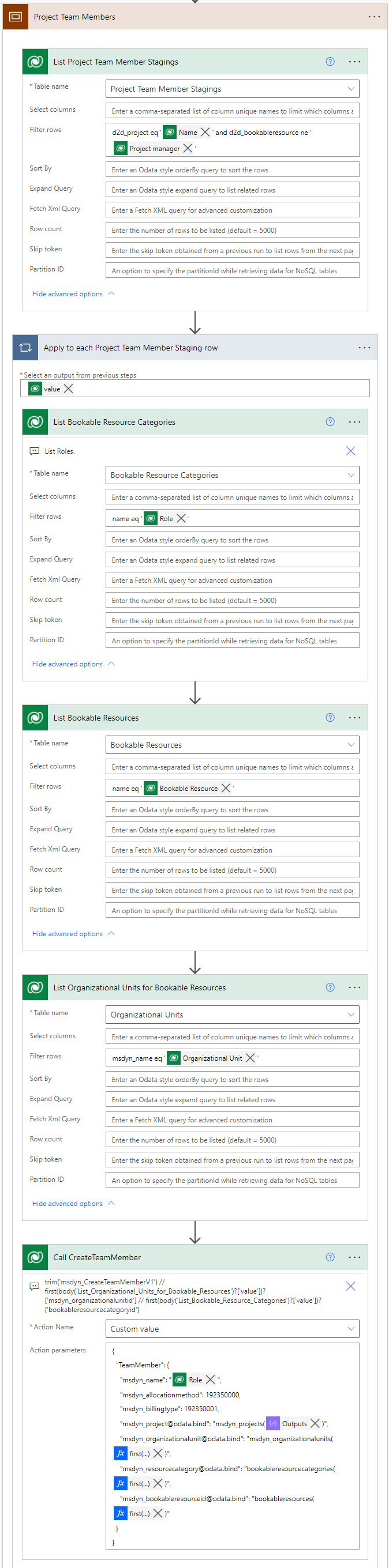
The scope after the condition is for creating Project Team Members. The action for creating PTMs doesn’t require an OperationSet so the first action in the Project Team Members scope is for listing Project Team Members Staging rows. The OData filter query filters out the Project Team Member Staging row where the value for Bookable Resource matches the value of the Project Staging row’s Project Manager column. This filtering is done as the PTM row for that specific Bookable Resource has already been created when creating the Project row in question. In other words, we’re only interested in creating PTM rows for Bookable Resouces who are not the related project’s PM.
The apply to each loop loops through the Project Team Member Staging rows listed in the previous action. Roles, Bookable Resources, and Organizational Units are then listed based on values on the Project Team Member Staging row that’s being looped through. The final action in the scope then creates new Project Team Member rows by calling the msdyn_CreateTeamMemberV1 unbound action and API. The JSON schema used for action parameters is below. Note the first expressions used for escaping additional apply to each loops from the list rows actions.
{
"TeamMember": {
"msdyn_name": "@{items('Apply_to_each_Project_Team_Member_Staging_row')?['d2d_role']}",
"msdyn_allocationmethod": 192350000,
"msdyn_billingtype": 192350001,
"msdyn_project@odata.bind": "msdyn_projects(@{outputs('Project')})",
"msdyn_organizationalunit@odata.bind": "msdyn_organizationalunits(@{first(body('List_Organizational_Units_for_Bookable_Resources')?['value'])?['msdyn_organizationalunitid']})",
"msdyn_resourcecategory@odata.bind": "bookableresourcecategories(@{first(body('List_Bookable_Resource_Categories')?['value'])?['bookableresourcecategoryid']})",
"msdyn_bookableresourceid@odata.bind": "bookableresources(@{first(body('List_Bookable_Resources')?['value'])?['bookableresourceid']})"
}
}
The final scope is for creating Resource Assignments. The first action in the scope is for listing Resource Assignment Staging rows that are related to the Project in question. RAs require an OperationSet so a new one is created. Resource Assignment Staging rows are then looped through in an apply to each. The first action in the loop is for listing Project Team Member rows created in the previous scope. This is where things get just a little bit more complicated: A PTM row doesn’t have a value for the related Bookable Resource. Instead, it has a lookup to Bookable Resource. We’re interested in PTM rows that are related to the Project row in question but which are also related to the same Bookable Resouce that we’re looping through in the apply to each. This means we have to use FetchXML to get what we’re looking for. Not a problem with MVP Jonas Rapp’s FetchXML Builder in XrmToolBox. The FetchXML used is:
<fetch top="5000">
<entity name="msdyn_projectteam">
<all-attributes />
<filter>
<condition attribute="msdyn_project" operator="eq" value="@{outputs('Project')}" />
</filter>
<filter>
<condition attribute="msdyn_bookableresourceidname" operator="eq" value="@{items('Apply_to_each_Resource_Assignment_Staging_row')?['d2d_projectteammember']}" />
</filter>
</entity>
</fetch>The following action then lists all Project Tasks that are related to the Project row in question, and which have matching values for subject (msdyn_subject) and Display Sequence as the Resource Assignment Staging row that’s being looped through. At this point, we have everything we need for creating new Resource Assignment rows. The msdyn_PssCreateV1 unbound action and API are then called and new RA rows are created. The JSON schema for the action is:
{
"msdyn_name": "@{items('Apply_to_each_Resource_Assignment_Staging_row')?['d2d_name']}",
"@{variables('varOdataType')}": "Microsoft.Dynamics.CRM.msdyn_resourceassignment",
"msdyn_projectid@odata.bind": "msdyn_projects(@{outputs('Project')})",
"msdyn_projectteamid@odata.bind": "msdyn_projectteams(@{first(body('List_Project_Team_Members')?['value'])?['msdyn_projectteamid']})",
"msdyn_taskid@odata.bind": "msdyn_projecttasks(@{first(body('List_Project_Tasks')?['value'])?['msdyn_projecttaskid']})"
}We’re nearly done! After the OperationSet is executed, the Project Staging row is updated to indicate that a new Project row has been created in Project Operations (or in P4W if that is your use case). The final action would benefit from error handling steps and a delay could also be used before updating the Project Staging row.

Sample flows
Sample solutions with flows are available on GitHub.
Author’s Effort and References
| Build and Write Effort | Community Blogs and Forums | MVPs Consulted | Product Group Interactions | Support Requests |
| Approximately 4 days | 0 | 0 | 0 | 0 |
Hello,
Great post and hands-on explanation! Just like your other P4W post 🙂
Happy I discovered your blog.
One question though in regards of a question I had recently with a customer.
They want to have a template for P4W and not Project operations. (like provision a project when an external system triggers the flow)
In the project schedule API documenation I can see there is a CopyProjectV3 action that can be used.
Does this also work for P4W only (I always seem to get an error)? Or is this a D365 operations kind of thing only (this one worked)?
I used a SharePoint list where i configured task which I then loop to create some buckets/tasks/…
Now that I read this post, it should also be possible to create a P4W ‘template’ and loop all tasks to ‘migrate’ to the same environment, right?
Might be something I should rework in the future.
Thanks!
Hi 🙂 I think copy project should also work for P4W. You should be able to create a template and loop back, yes. Just remember transactional consistency with the schedule APIs.