
Tested on Project Operations Lite solution version 4.26.0.155 (November 2021), Project for the web solution version 1.0.26.153
Edited: March 8th, 2022.
The Project schedule APIs are the only means of programmatically creating, updating, and deleting Scheduling tables in both Project Operations and Project for the web. This blog post serves as a guide to programmatically creating rows in the Scheduling tables by using Power Automate. We’ll run through all the different tables that require the APIs and the different unbound actions for calling them. We’ll also look at the scheduling engine and its limitations in more detail.
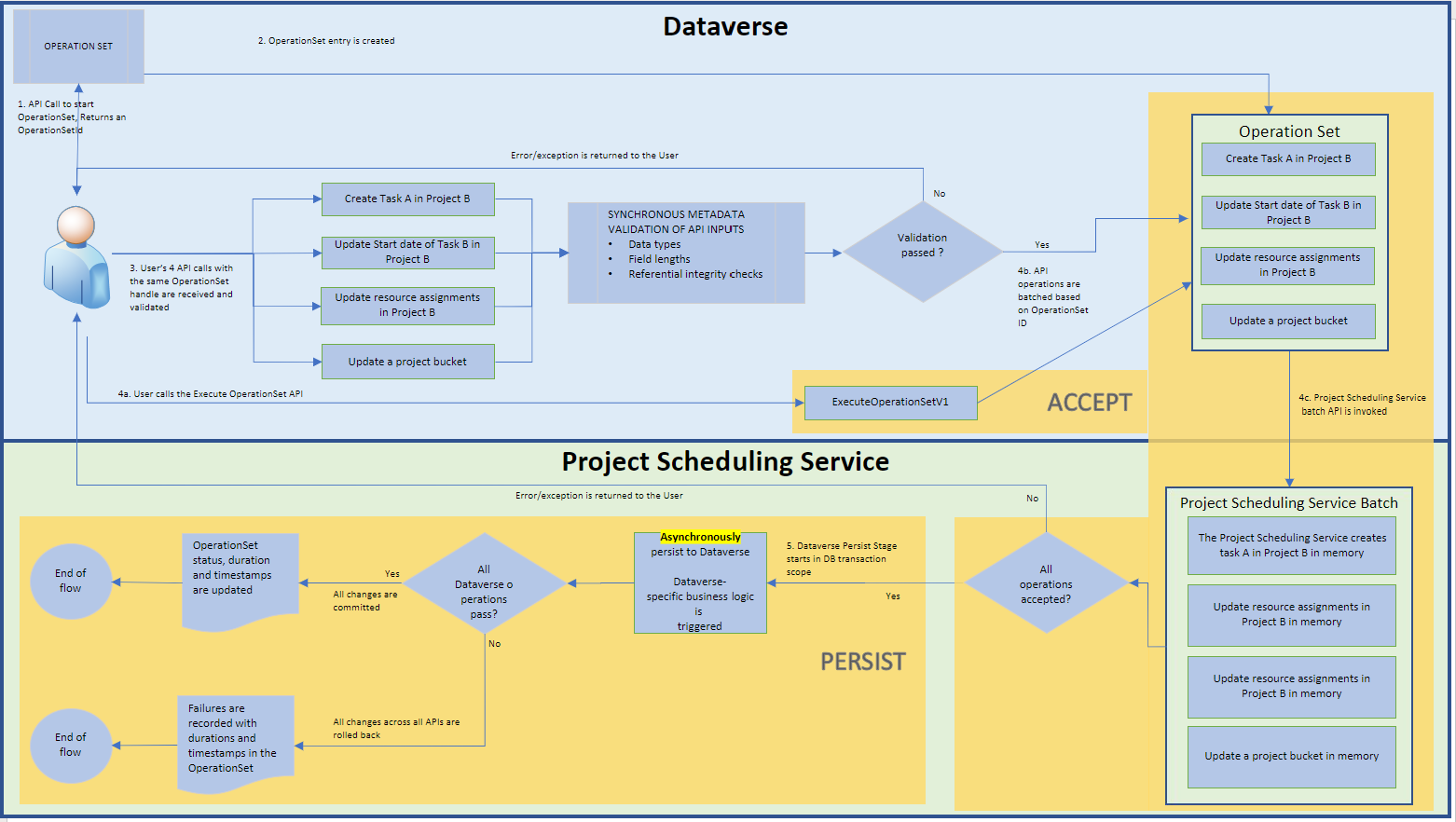
Project Scheduling Service – PSS
Scheduling tables can’t be updated directly in Dataverse so the APIs were created as a means of executing CUD (create, update, delete) operations against Project Scheduling Service (PSS), which is the Azure Service React hosted scheduling engine for Project for the web.
PSS solves problems Dataverse isn’t good at. Transactional processing at high volumes is fast with PSS and it allows for co-authoring of a WBS. The downside is that as the Project for the web UI talks directly to a Calculation Service reliable actor instance on Service Fabric, changes made are not immediately persisted to Dataverse. The Calculation Service reliable actor instance has to first accept changes and the Save Service reliable actor has to then persist the changes to Dataverse. This accept vs. persist problem also presents a problem with transaction consistency, which we’ll look at a bit later in this post.
In a real-life scenario, an accept vs. persist problem can be seen as a somewhat cryptic error that states that Project for the web wasn’t able to stick to changes you’ve made in the UI. Then again we don’t have to live with PSA’s scheduling plugins anymore so it’s really a “you win some you lose some” deal.
So what is Project in Project for the web then? That’s a good question. The Calculation Service reliable actor instance hosts winproj.exe. That’s why we’re able to use .MPP files with vanilla Project for the web. Some capabilities aren’t available in Project for the web, and that’s why schedules in the Project desktop app have richer features. As winproj.exe is behind it all in Project for the web, it’s possible the product team introduces more capabilities to Project for the web down the line.
Schedule APIs
The schedule APIs are a set of custom actions that are called like any other unbound action in Dataverse. The Scheduling tables and all the actions are clearly listed on docs so there’s little point in re-writing that content to the letter in this blog post. When calling the APIs, batch processing and transactional consistency should always be considered. As multiple changes can be batched together, all changes either succeed or fail. The APIs do have some limitations, which are important to understand. I recommend you to read through the docs article. Another point I want to make about the APIs is their usability. While they can be called from Power Automate, they might be significantly faster to call using C# as building all the logic for calling them is fairly time-consuming in Power Automate.
Limitations of PSS
Like previously mentioned, the Calculation Service in PSS accepts a change, and the Save Service then runs asynchronously and persists the change to Dataverse. Before this asynchronous operation has successfully persisted a change, there are no guarantees that a request sent to PSS will succeed. An example could be where a delete operation is sent to PSS to delete a project task. While the Calculation Service in PSS will accept the operation, the Save Service might fail to persist the change if the task in question has an Actual related to it (via an approved time entry for example).
Another limitation of PSS is the fact that the entire scheduling login can’t be customized at all. This is understandable as PSS wouldn’t be aware of any operations made directly to Dataverse. If something changed in Dataverse while in-between accept and persists, PSS wouldn’t be aware of it. This is why direct CUD operations to Scheduling tables in Dataverse are blocked. Another example could be a pre-operation plugin, which updates the value PSS is trying to persist. If this was possible, PSS would not be aware of the change.
Transactional consistency
We now know that the accept vs. persist problem means that changes accepted may not be persisted to Dataverse. This means that any logic built around schedule APIs must be architected with care! If there is a scenario where a CUD operation in Dataverse leads to calling the schedule APIs, transactional consistency may be hard if not impossible to achieve. For example, if a project task should be updated after a service task is updated in Field Service, transactional consistency may not be achieved if updating the project task is not persisted to Dataverse. The result may be a service task with inconsistent data compared to the project task.
Transactional consistency can be achieved by re-thinking the aforementioned scenario. A route-through pattern should be used for scenarios involving PSS. Essentially it means that the logic should be routed through PSS first and changes made to Dataverse should follow a successful persist. In the aforementioned scenario, transactional consistency can be achieved by updating the project task first and the service task second, after a successful persist.
By querying an Operation Set’s status, we’re able to know whether or not changes have been persisted: If the status of an Operation Set is Completed, all changes are persisted. There’s a good article on docs about this. I strongly recommend you read it.
Calling schdule APIs from Power Automate
Let’s look at how the different APIs are called from Power Automate. It’s important to check docs for what is supported with the different Scheduling tables before building any automation. The purpose of this chapter is to illustrate how the different actions are called from flow and to highlight some gotchas and considerations. The flow covered in this blog post runs through the following scenarios:
- Create a new Project.
- Create a new Project Team Member.
- Create a new Project Bucket.
- Create a new Project Task as a summary (parent) task.
- Create two new Project Tasks as subtasks (child tasks).
- Create a new Project Task Dependency.
- Create two new Resource Assignments.
- Update a previously created subtask.
- Validate that changes are persisted to Dataverse.
Before we move forward I want to emphasize that the flow we’re covering is a test flow and has hard-coded values for different rows on purpose. Feel free to edit the flow to your liking.
The schdedule API demo flow
I’ve built two different demo flows, which are both available on GitHub. This blog post runs through the Project Operations version of the flow, with the other version being for vanilla Project for the web. Some actions require slightly different approaches, depending on the product. I’ll highlight these differences as we walk through the flow. Let’s get started.
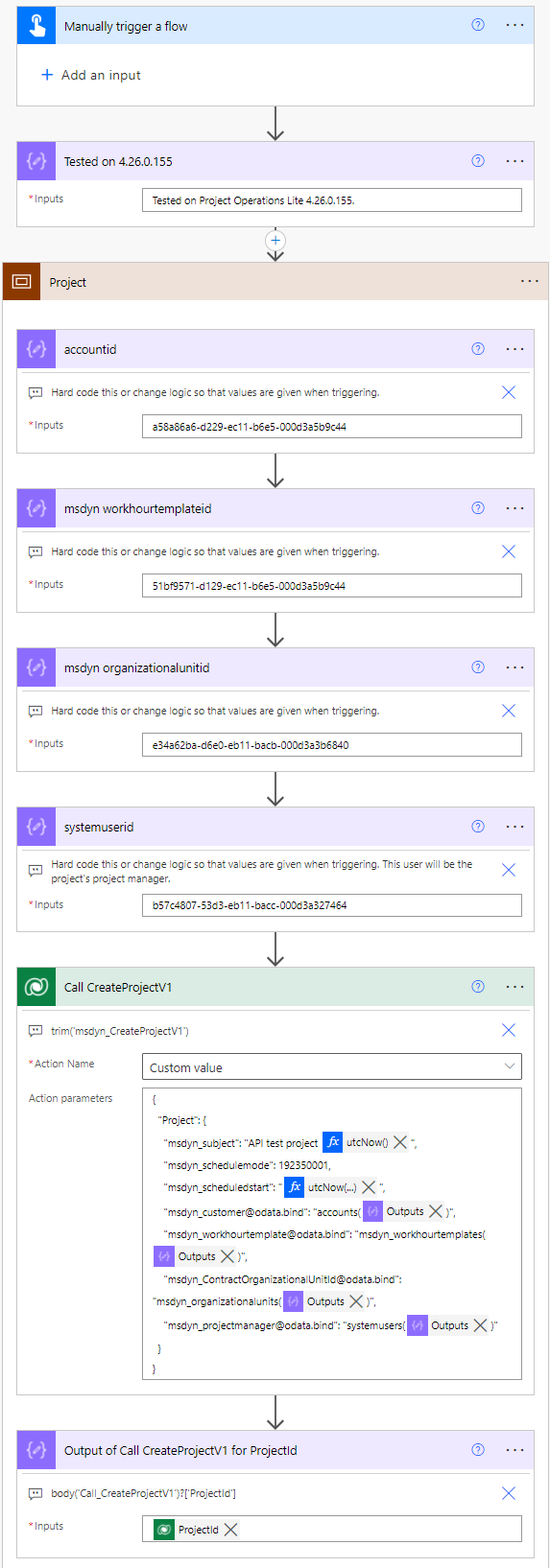
Project
A Project row has business required lookups to different tables, which are listed below. The account table is not required but I’ve nevertheless included it as it has significant meaning in a Project Operations project. Note that vanilla Project for the web doesn’t have a relationship between account and msdyn_project!
- Lookup to msdyn_workhourtemplate table.
- Lookup to msdyn_organizationalunit table.
- Lookup to systemuser table.
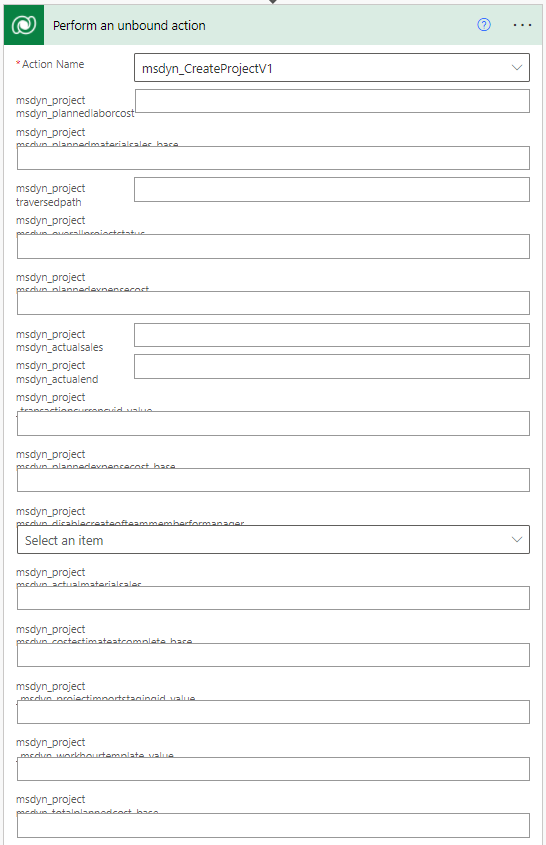
To create a project row, call the msdyn_CreateProjectV1 API by calling the unbound action msdyn_CreateProjectV1. This API doesn’t require an Operation Set and calling it creates both a project and a default bucket. If the unbound action is added in Power Automate without using a trim('msdyn_CreateProjectV1') expression, the action will render as partly unreadable in the Power Automate editor (see image 1 below). A trim expression will reveal action parameters, which accept JSON as input.
As this is a test flow, GUIDs for various rows have been hard-coded in compose actions. Replace the values with your own when testing the flow in your environment. For testing purposes, date values for columns such as msdyn_scheduledstart can be entered with a utcNow expression utcNow('yyyy-MM-dd').
When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive. As can be seen from the sample JSON below, some values are lower-case only while some contain a combination of upper and lower-case letters.
{
"Project": {
"msdyn_subject": "API test project",
"msdyn_schedulemode": 192350001,
"msdyn_scheduledstart": "value here",
"msdyn_customer@odata.bind": "accounts(accountid value here)",
"msdyn_workhourtemplate@odata.bind": "msdyn_workhourtemplates(msdyn_workhourtemplateid value here)",
"msdyn_ContractOrganizationalUnitId@odata.bind": "msdyn_organizationalunits(msdyn_organizationalunitid value here)",
"msdyn_projectmanager@odata.bind": "systemusers(systemuserid value here)"
}
}The resulting GUID for the project the action creates can be composed using body('Call_CreateProjectV1')?['ProjectId'].
Project for the web specific differences with the Project table
- No relationship between account and msdyn_project.
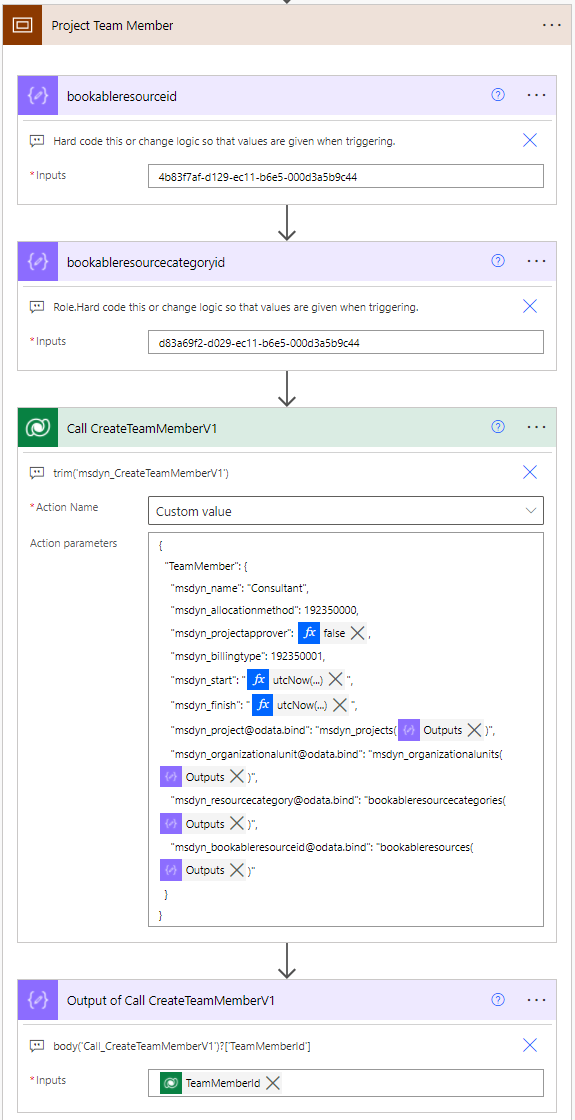
Project Team Member
A Project Team Member (later PTM) row has business required lookups and other columns, which are listed below. I have also included some columns frequently used in the creation of a PTM row. Note that vanilla Project for the web doesn’t have the msdyn_billingtype column!
- Lookup to msdyn_project table
- Lookup to msdyn_organizationalunit table
- Lookup to bookableresourcecategory table
- Lookup to bookableresource table
- msdyn_start column
- msdyn_finish column
To create a PTM row, call the msdyn_CreateTeamMemberV1 API by calling the unbound action msdyn_CreateTeamMemberV1. This API doesn’t require an Operation Set and calling it creates a PTM. If the unbound action is added in Power Automate without using a trim('msdyn_CreateTeamMemberV1') expression, the action will render as partly unreadable in the Power Automate editor. A trim expression will reveal action parameters, which accept JSON as input.
As this is a test flow, GUIDs for various rows have been hard-coded in compose actions. Replace the values with your own when testing the flow in your environment. For testing purposes, date values for columns such as msdyn_start and msdyn_finish can be entered with a utcNow expression utcNow('yyyy-MM-dd').
When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive. Sample JSON for this API can be found below.
{
"TeamMember": {
"msdyn_name": "Consultant",
"msdyn_allocationmethod": 192350000,
"msdyn_projectapprover": true or false,
"msdyn_billingtype": 192350001,
"msdyn_start": "value here",
"msdyn_finish": "value here",
"msdyn_project@odata.bind": "msdyn_projects(msdyn_projectid valuehere)",
"msdyn_organizationalunit@odata.bind": "msdyn_organizationalunits(msdyn_organizationalunitid value here)",
"msdyn_resourcecategory@odata.bind": "bookableresourcecategories(bookableresourcecategoryid value here)",
"msdyn_bookableresourceid@odata.bind": "bookableresources(bookableresourceid value here)"
}
} The resulting GUID for the PTM the action creates can be composed using body('Call_CreateTeamMemberV1')?['TeamMemberId'].
Project for the web specific differences with the PTM table
- No msdyn_billingtype column.
Operation Sets
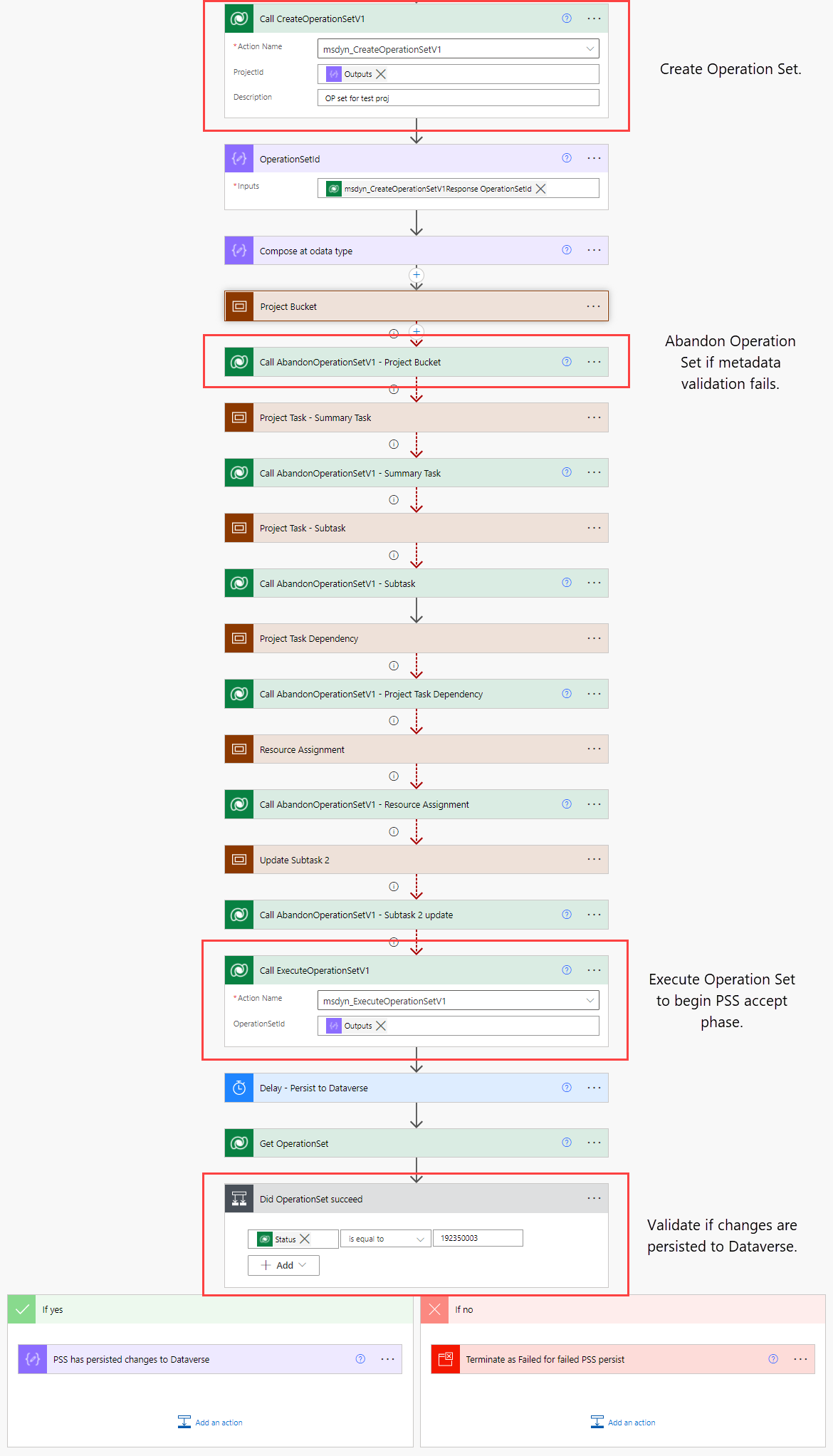
The APIs listed below are an exception to the previously mentioned Project and PTM APIs and are called within the context of an Operation Set. An Operation Set is first created with the msdyn_CreateOperationSetV1 API, schedule APIs are then called and the operations are batched together, and the Operation Set is then executed to begin the PSS accept phase. More information can be found on docs.
APIs requiring an Operation Set
- msdyn_PssCreateV1
- msdyn_PssUpdateV1
- msdyn_PssDeleteV1
If synchronous metadata validation fails when one of the aforementioned APIs is called, an open Operation Set can be abandoned by calling the msdyn_AbandonOperationSetV1 API with the msdyn_AbandonOperationSetV1 unbound action. This way the open Operation Set limit of 10 can be avoided when testing with Power Automate.
After an Operation Set is executed by calling the msdyn_ExecuteOperationSetV1 API with the msdyn_ExecuteOperationSetV1 unbound action, a delay is required for PSS to persist changes to Dataverse. The time it takes for PSS to asynchronously persist changes depends on the changes being made. Docs have a section on results, which gives an indication of how much time PSS needs. If using plugins or Azure Functions, remember to consider possible timeouts in your logic.
After a delay, the status of the executed Operation Set can be validated. If the Operation Set’s msdyn_status column has a value of 192350003 (Completed), all changes have persisted to Dataverse. Additional logic post routing through PSS can be processed further from this point forward.
Project Bucket
A Project Bucket (later bucket) row has a business required lookup to the msdyn_project table. The column msdyn_name is used for a bucket’s name.
Creating a Project Bucket with the native Dataverse connector
A bucket row can be created by using the Dataverse connector’s Add a new row action. It isn’t necessary to call the msdyn_PssCreateV1 API to create a new Project Bucket. An example can be found on docs.
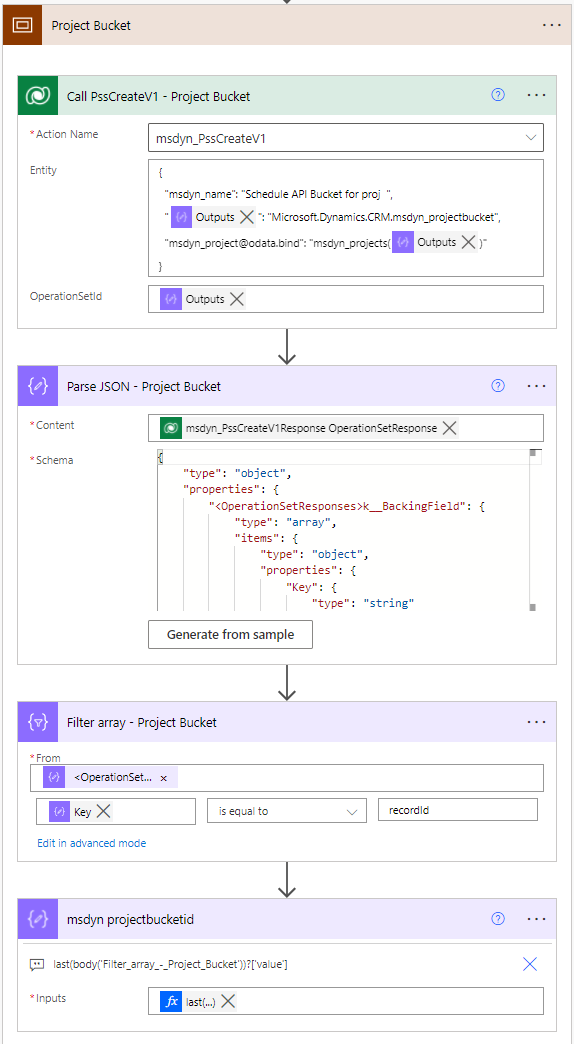
Creating a Project Bucket with the schedule API msdyn_PssCreateV1
A bucket row can also be created by calling the msdyn_PssCreateV1 API by calling the unbound action msdyn_PssCreateV1. This API requires an Operation Set. The action’s entity parameters take JSON as input, and a sample JSON can be found below. When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive.
{
"msdyn_name": "Schedule API Bucket for proj",
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_projectbucket",
"msdyn_project@odata.bind": "msdyn_projects(msdyn_projectid value here)"
}In image 5, a compose action’s output is used for @odata.type as typing an @ in the JSON directly would require for it to be escaped with another @. The resulting GUID for the bucket the action creates can be obtained from the Key property’s value in the action’s output. To get to the property, a parse JSON and a filter array are used. A compose action with the following expression is then used to compose the value: last(body('Filter_array_-_Project_Bucket'))?['value'].
Project for the web specific differences with the Project Bucket table
- No differences found.
Project Task
A Project Task (later task) row has business required lookups and other columns, which are listed below. While the Role and Organizational Unit lookups have their use cases in multi-role assignments, those columns for the Project Task table are not covered in this blog post. I have also included some columns frequently used in the creation of a task row. Note that vanilla Project for the web doesn’t have the msdyn_LinkStatus column as it’s related to task-based billing.
- Lookup to msdyn_project table
- Lookup to msdyn_projectbucket table
- Lookup to msdyn_projecttask (self-referential)
- msdyn_start column
- msdyn_finish column
- msdyn_LinkStatus column
- msdyn_outlinelevel column
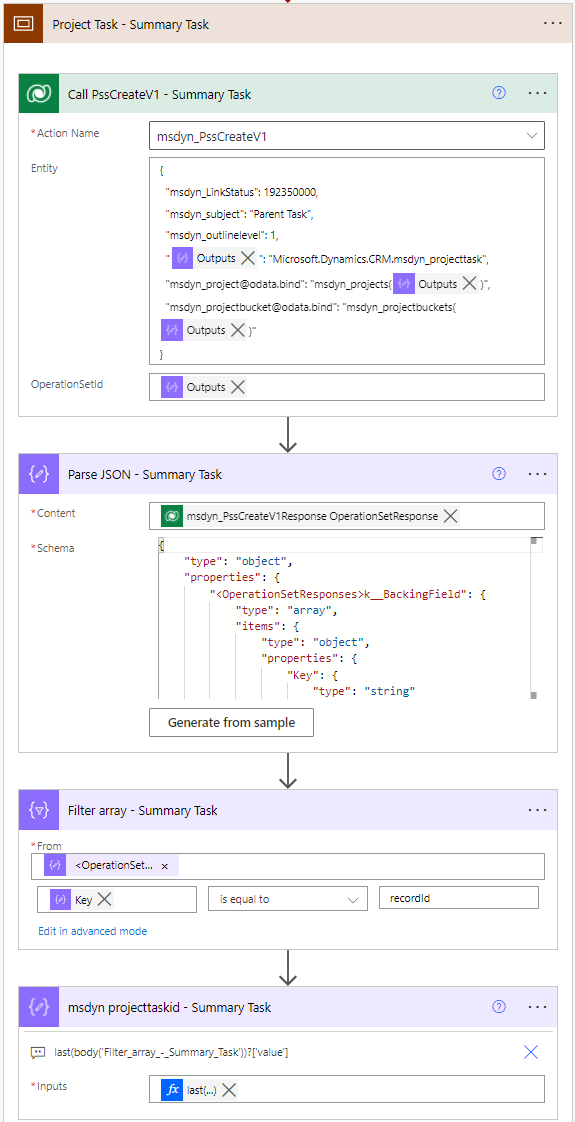
To create a task row, call the msdyn_PssCreateV1 API by calling the unbound action msdyn_PssCreateV1. This API requires an Operation Set. The action’s entity parameters take JSON as input, and a sample JSON can be found further below. When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive.
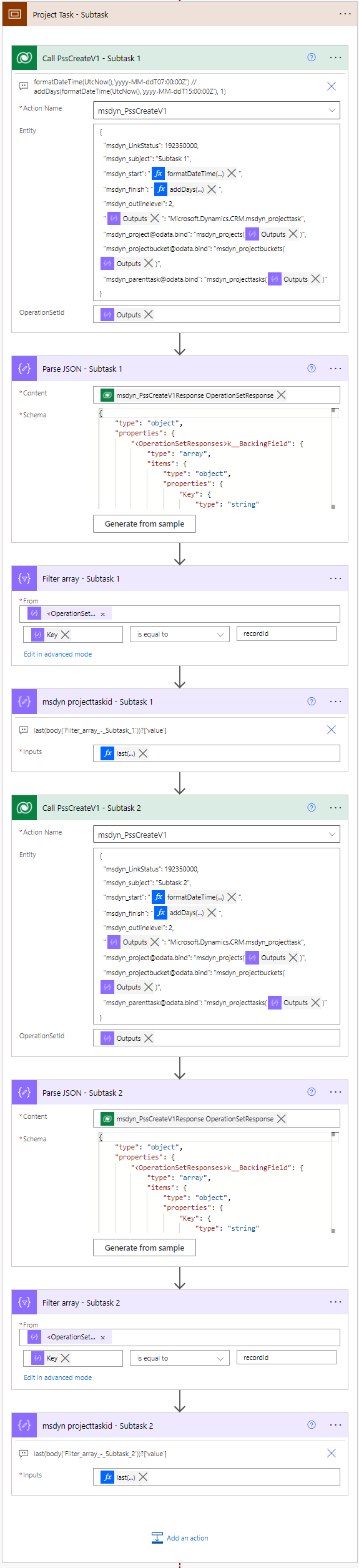
When creating a new task, a summary task (parent task) is created with msdyn_outlinelevel set to 1. Subtasks (child tasks) are created with msdyn_outlinelevel set to 2. The msdyn_parenttask navigation property with the @odata.bind annotation is used to link summary tasks and subtasks together. PSS seems to create tasks in the order in which it receives changes and there’s no WBS ID concept known from Project Service Automation unless Display Sequence (msdyn_displaysequence) is used to insert tasks in a WBS in a specific order. You can read more about Display Sequence at the end of this blog. Pay very close attention to docs to understand which columns can be updated with the API.
The following JSON can be used for the action’s entity parameter input to create summary tasks:
{
"msdyn_LinkStatus": 192350000,
"msdyn_subject": "Parent Task",
"msdyn_outlinelevel": 1,
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_projecttask",
"msdyn_project@odata.bind": "msdyn_projects(msdyn_projectid value here)",
"msdyn_projectbucket@odata.bind": "msdyn_projectbuckets(msdyn_projectbucketid value here)"
}In images 6 and 7, a compose action’s output is used for @odata.type as typing an @ in the JSON directly would require for it to be escaped with another @. The resulting GUID for the bucket the action creates can be obtained from the Key property’s value in the action’s output. To get to the property, a parse JSON and a filter array are used. A compose action with the following expression is then used to compose the value: last(body('Filter_array_-_SummaryOrSubtask'))?['value'] .
The following JSON can be used for the action’s entity parameter input to create subtasks:
{
"msdyn_LinkStatus": 192350000,
"msdyn_subject": "Subtask 1",
"msdyn_start": "value here",
"msdyn_finish": "value here",
"msdyn_outlinelevel": 2,
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_projecttask",
"msdyn_project@odata.bind": "msdyn_projects(msdyn_prijectid value here)",
"msdyn_projectbucket@odata.bind": "msdyn_projectbuckets(msdyn_projectbucketidvalue here)",
"msdyn_parenttask@odata.bind": "msdyn_projecttasks(msdyn_projecttaskid value here)"
}
Project for the web specific differences with the Project Task table
- No msdyn_LinkStatus column.
- Notable differences in allowed CUD operations for several columns. See Docs for more information.
Project Task Dependency
A Project Task Dependency (later dependency) row has business required lookups, which are listed below. Note that vanilla Project for the web doesn’t have the msdyn_linktype column! While the choice columns indicate new task dependency types are on the horizon, the only supported dependency type at the time of writing this blog post is Finish-to-Start.
- Lookup to msdyn_project table
- Lookup to msdyn_projecttask (for msdyn_PredecessorTask and msdyn_SuccessorTask navigation properties)
- msdyn_linktype (Project Operations only)
- msdyn_projecttaskdependencylinktype
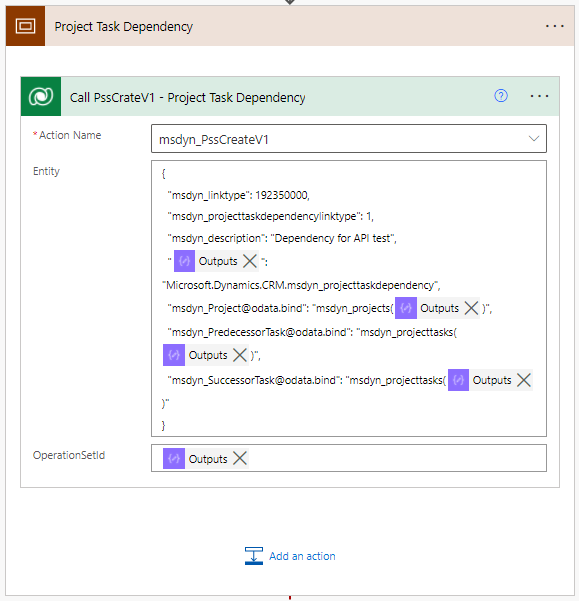
To create a dependency row, call the msdyn_PssCreateV1 API by calling the unbound action msdyn_PssCreateV1. This API requires an Operation Set. The action’s entity parameters take JSON as input, and a sample JSON can be found further below. When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive.
When creating a dependency, there are two columns, which both seem to point to task dependency types. As I’m writing this post I’ve yet to discern the difference between msdyn_linktype and msdyn_projecttaskdependencylinktype. Project Operations has msdyn_linktype but vanilla Project for the web doesn’t. The choice column values are also significantly different in their value naming convention, as can be seen from image 8 below.

The following JSON can be used for the action’s entity parameter input to create a dependency:
{
"msdyn_linktype": 192350000,
"msdyn_projecttaskdependencylinktype": 1,
"msdyn_description": "Dependency for API test",
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_projecttaskdependency",
"msdyn_Project@odata.bind": "msdyn_projects(msdyn_projectid value here)",
"msdyn_PredecessorTask@odata.bind": "msdyn_projecttasks('msdyn_projecttaskid value here)",
"msdyn_SuccessorTask@odata.bind": "msdyn_projecttasks(msdyn_projecttaskid value here)"
}
Project for the web specific differences with the Project Task Dependency table
- No msdyn_linktype column.
Resource Assignment
A Resource Assignment (later RA) row has business required lookups, which are listed below.
- Lookup to msdyn_project table
- Lookup to msdyn_projectteam table
- msdyn_projecttask table
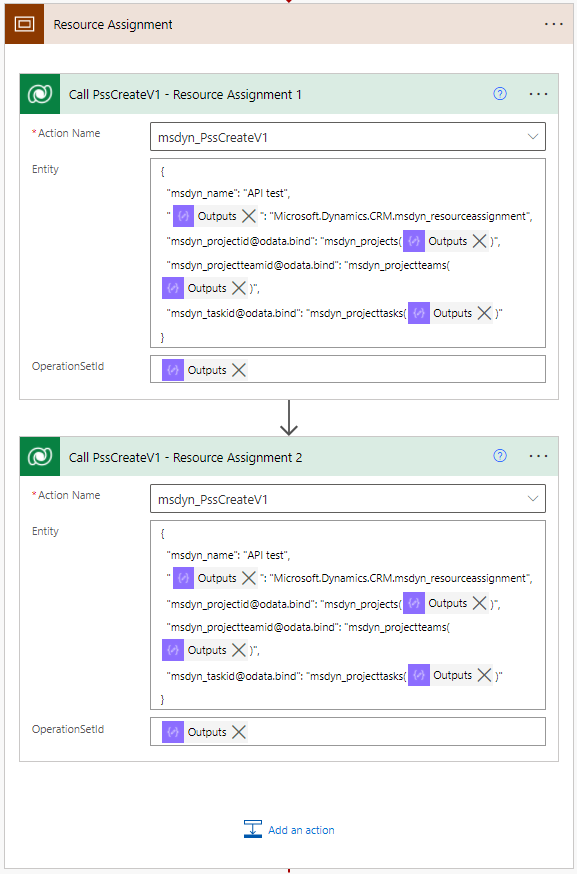
To create an RA row, call the msdyn_PssCreateV1 API by calling the unbound action msdyn_PssCreateV1. This API requires an Operation Set. The action’s entity parameters take JSON as input, and a sample JSON can be found below. When setting a value of a navigation property using the @odata.bind annotation, remember that navigation property values are case-sensitive.
{
"msdyn_name": "API test",
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_resourceassignment",
"msdyn_projectid@odata.bind": "msdyn_projects(msdyn_projectid value here)",
"msdyn_projectteamid@odata.bind": "msdyn_projectteams(msdyn_projectteamid value here)",
"msdyn_taskid@odata.bind": "msdyn_projecttasks('msdyn_projecttaskid value here)"
}
Project for the web specific differences with the Project Task table
- No differences found.
Update operations with msdyn_PssUpdateV1
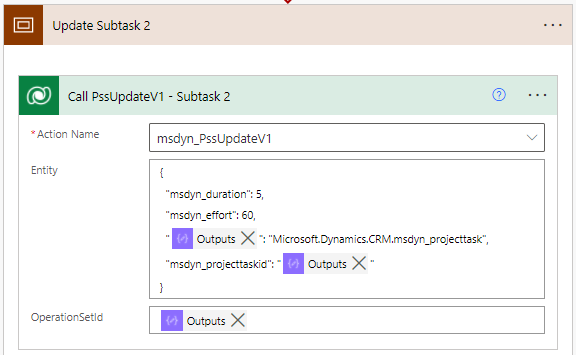
To update rows, call the msdyn_PssUpdateV1 API by calling the unbound action msdyn_PssUpdateV1. This API requires an Operation Set. The action’s entity parameters take JSON as input, and a sample JSON can be found below. The example JSON updates a Project Task inside the same Operation Set in which the task is also created.
{
"msdyn_duration": 5,
"msdyn_effort": 60,
"@odata.type": "Microsoft.Dynamics.CRM.msdyn_projecttask",
"msdyn_projecttaskid": "msdyn_projecttaskid value here"
}
Delete operations with msdyn_PssDeleteV1
To delete rows, call the msdyn_PssDeleteV1 API by calling the unbound action msdyn_PssDeleteV1. This API requires an Operation Set, and its input parameters are EntityLogicalName, RecordId, and OperationSetId.
The scope in image 12 is not included in the provided sample flows!
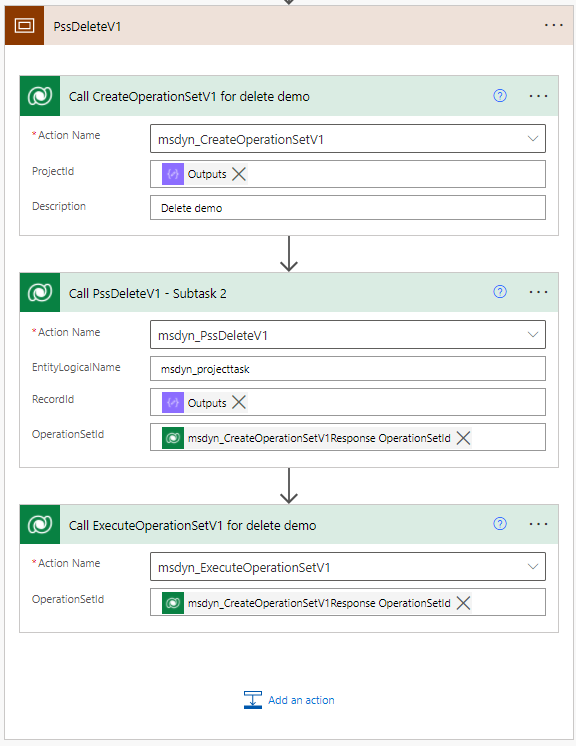
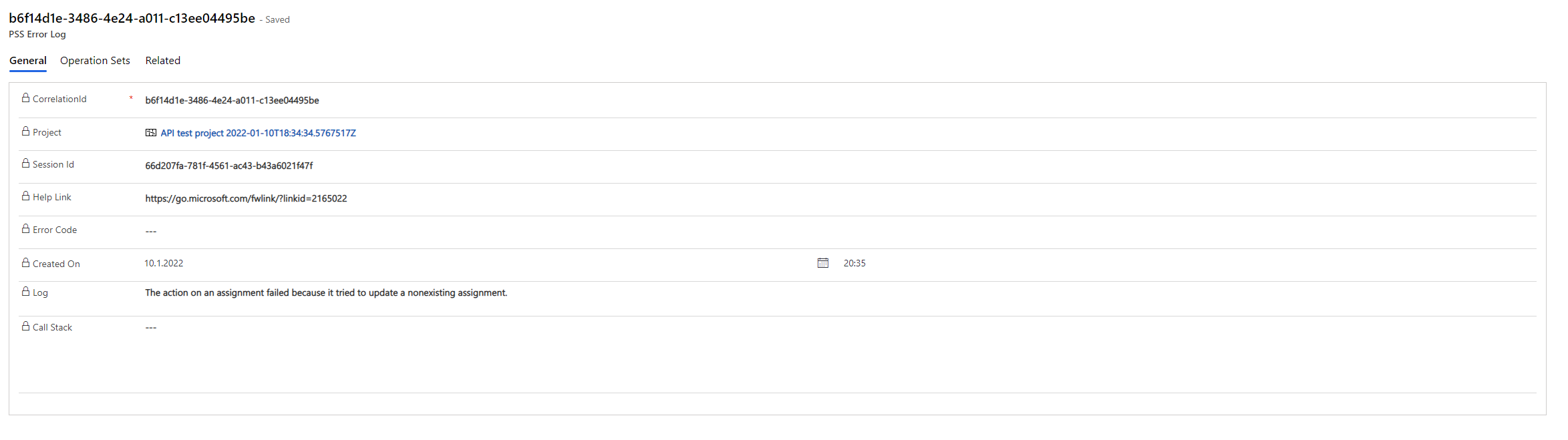
Analyzing failed PSS persists
If PSS fails to persist changes to Dataverse, a PSS Error Log row is created in the PSS Error Log table. The logs provide a means of diagnosing PSS persist errors. Image 13 shows an error log for a scenario where a Resource Assignment is created but the related Project Task is then deleted in the same Operations Set.
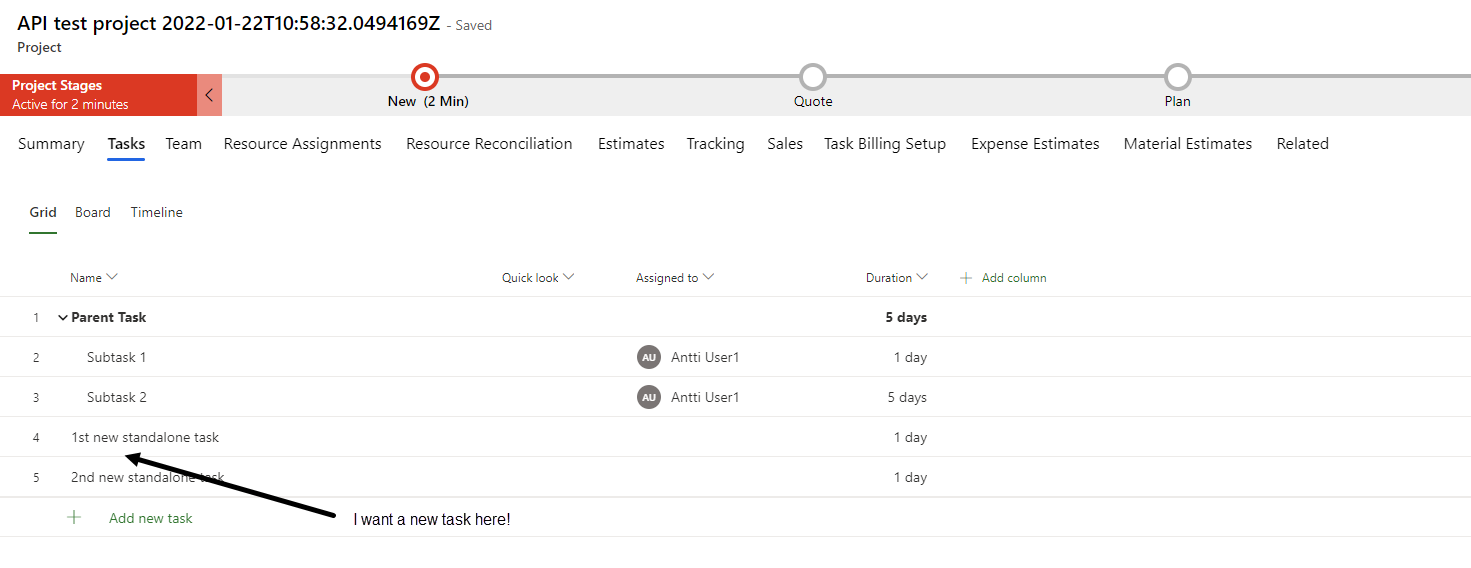
Using Display Sequence to insert tasks in a specific order
Display Sequence is a column that can be used to insert project tasks to a WBS in a specific order. The column is a decimal number column and it supports 9 decimal places. Let’s consider the following scenario: We want to insert two tasks after task 4 seen in image 14. If we look at the Display Sequence of the tasks, task 4’s Display Sequence will be 5 as Display Sequences start at 2. Display Sequence of task 5 is thus 6.
To insert two new tasks after task 4 the new tasks need a Display Sequence that’s something between 5 and 6. The values could be, for example, 5.1 and 5.2 or 5.001 and 5.002.
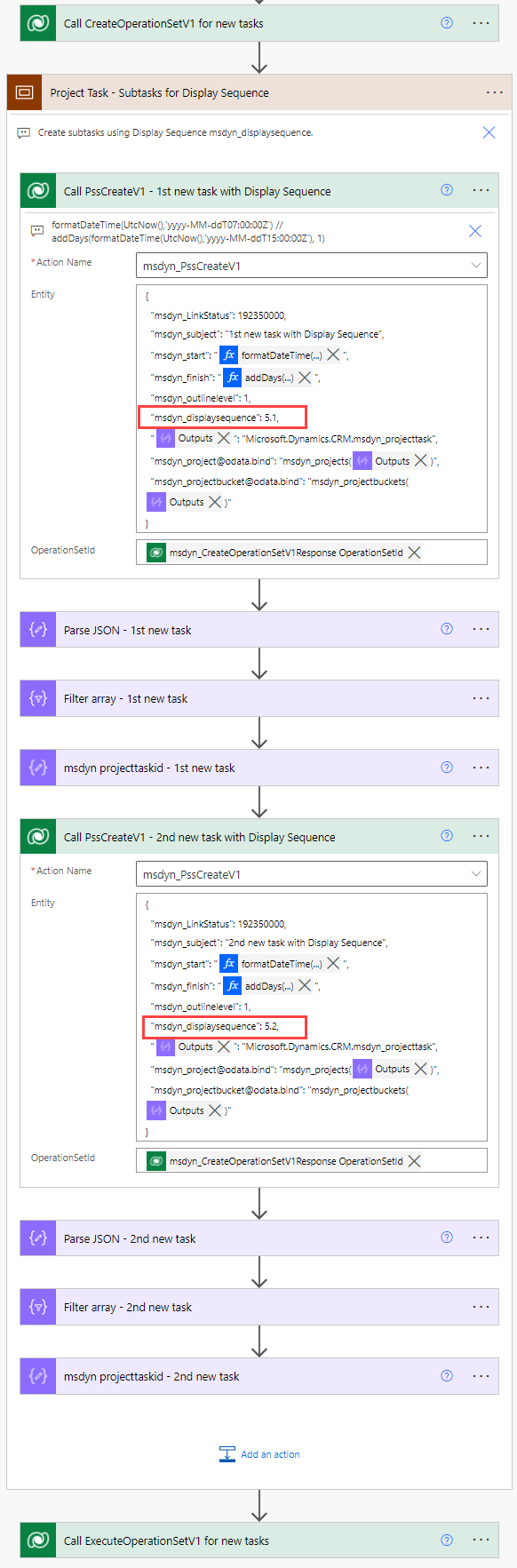
Display Sequence is simply an additional property in the JSON schema for creating project tasks. Image 15 shows how two new tasks can be created between tasks 4 and 5 by using Display Sequence. As I’ve added the action after publishing the first version of the flow, the new tasks are created in a new Operation Set.
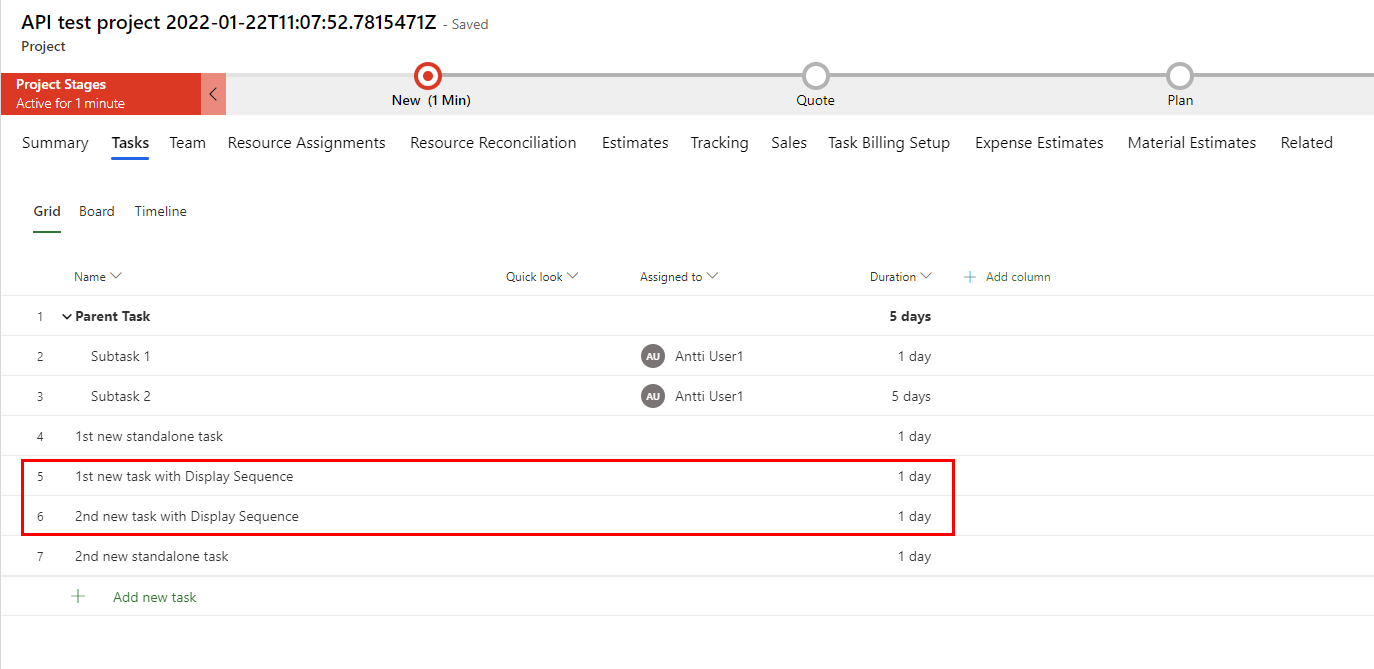
The result of using Display Sequence can be seen in images 16 and 17. The new tasks fall between tasks 4 and 5.

Sample flows
The sample flows for Project Operations and vanilla Project for the web scenarios can be found on GitHub. They’re provided “as is”.
Author’s Effort and References
| Build and Write Effort | Community Blogs and Forums | MVPs Consulted | Product Group Interactions | Support Requests |
| Approximately 2 days | 0 | 0 | 2 | 0 |
- Use Project schedule APIs to perform operations with Scheduling entities
- Project schedule API performance
- Configure chargeable components of a project-based contract line
- Associate table rows on create
Edits
January 22nd 2022:
- Added a chapter about Display Sequence.
- Added logic to the flow that adds two new tasks after original subtasks.
- Added logic to the flow that adds two new tasks between tasks 4 and 5 by using Display Sequence.
- Uploaded a new version of the Project Operations version of the flow to GitHub.
Antti, first let me see your posts have been a real resource for me….I really appreciate you putting this out on the web….What Microsoft has in many cases is wrong and it seems using unbound actions at this point verses hitting any of the tables directly is the only consistent way to go.
I am attempting to replicate the project task creation process in my own environment. Have been fairly successful with everything to date. However, I am stuck at the moment. In your Parse Json – Summary Task example above, what is the from in the Filter Array. Is it possible to post what you inputted there??
Thanks so much
Thanks Jay! The from for Filter array – Summary Task is:
@body('Parse_JSON_-_Summary_Task')?['k__BackingField']